We address the task of video style transfer with diffusion models, where the goal is to preserve the context of an input video while rendering it in a target style specified by a text prompt. A major challenge is the lack of paired video data for supervision. We propose PickStyle, a video-to-video style transfer framework that augments pretrained video diffusion backbones with style adapters and benefits from paired still image data with source–style correspondences for training. PickStyle inserts low-rank adapters into the self-attention layers of conditioning modules, enabling efficient specialization for motion–style transfer while maintaining strong alignment between video content and style. To bridge the gap between static image supervision and dynamic video, we construct synthetic training clips from paired images by applying shared augmentations that simulate camera motion, ensuring temporal priors are preserved. In addition, we introduce Context–Style Classifier-Free Guidance (CS–CFG), a novel factorization of classifier-free guidance into independent text (style) and video (context) directions. CS–CFG ensures that context is preserved in generated video while the style is effectively transferred. Experiments across benchmarks show that our approach achieves temporally coherent, style-faithful, and content-preserving video translations, outperforming existing baselines both qualitatively and quantitatively.
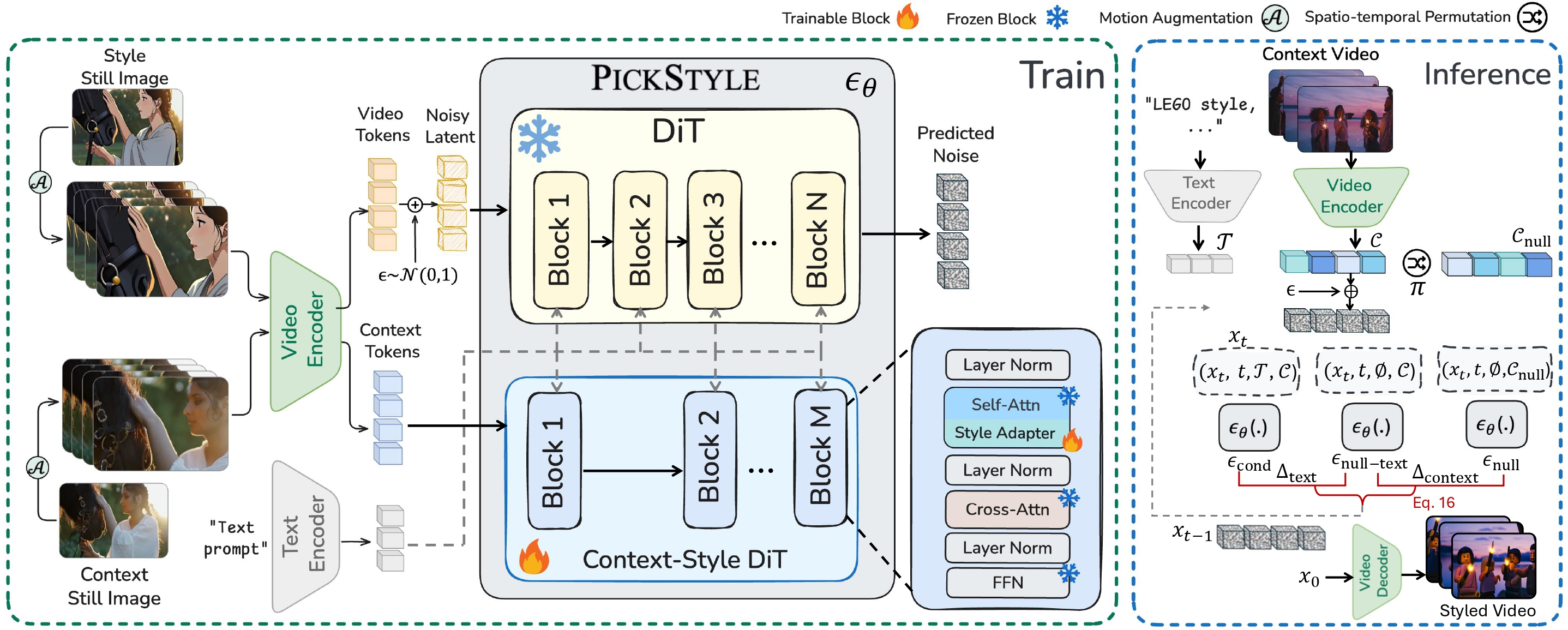
Training and inference pipeline of PickStyle. In training (left), both the style image and the context image are transformed into video tokens and context tokens with synthetic camera motion using motion augmentation; video tokens are noised and denoised conditioned on context tokens by the DiT-based PickStyle model with context-style adapters. In inference (right), a context video and a style description are encoded and iteratively denoised under text, context, and null conditions, where the proposed CS-CFG applies spatiotemporal permutation to the null context to generate the final styled video.